A reminder not to be overly impressed when presented with statistically significant coefficients, from FiveThirtyEight.com.
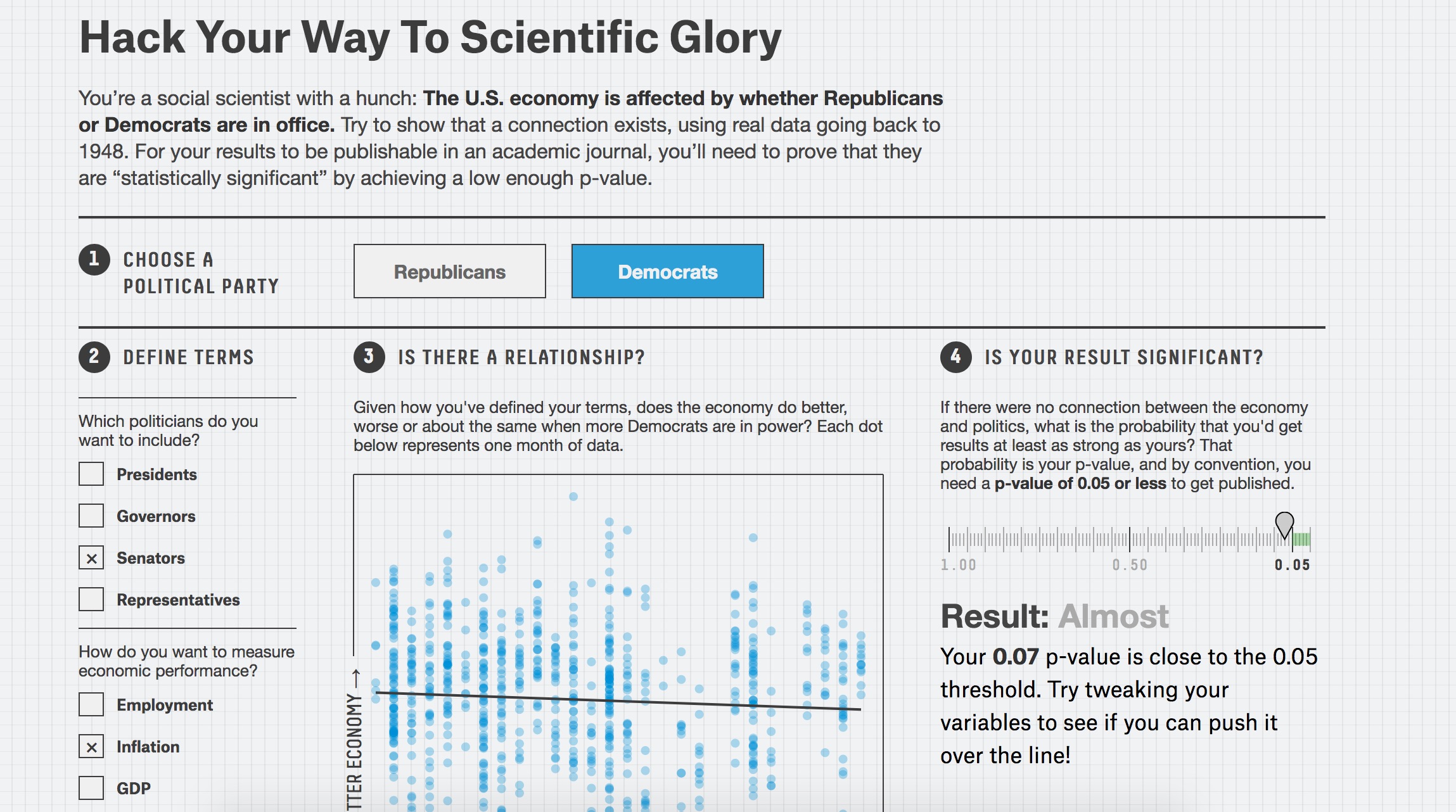

A reminder not to be overly impressed when presented with statistically significant coefficients, from FiveThirtyEight.com.
In separate blog posts, Russ Roberts and John Cochrane have called for humility on the part of economists. Asking “What do economists know?,” Roberts and Cochrane point out—correctly—that economics is not as strong on quantification as some economists and many pseudo economists pretend, and as is often expected from economists.
Economics is not the same as applied statistics although the latter can help clarify, at least to some extent, the empirical relevance of economic theories. Correlation does not imply causation. Identifying assumptions that aim at establishing causal claims based on correlation analysis deserve skepticism, especially when the process that led to the empirical results remains in the dark (see notes on replicability here, here, here).
Sound economics heavily relies on consistency checking, or bullshit detection in Cochrane’s words. It insists on keeping accounting identities in mind and never forgetting about incentives. And it is acutely aware of the fact that good models are nothing more than consistent stories—but at least they are consistent stories.
The Economist reports about research by Paul Smaldino and Richard McElreath indicating that studies in psychology, neuroscience and medicine have low statistical power (the probability to correctly reject a null hypothesis). If, nevertheless, almost all published studies contain significant results (i.e., rejections of null hypotheses), then this is suspicious.
Furthermore, Smaldino and McElreath’s research suggests that
the process of replication, by which published results are tested anew, is incapable of correcting the situation no matter how rigorously it is pursued.
With the help of a model of competing research institutes, Smaldino and McElreath simulate how empirical scientific research progresses. Labs that find more new results also tend to produce more false positives. More careful labs try to rule out false positives but publish less. More “successful” labs are allowed to replicate. As a consequence, less careful labs spread out. Replication—repetition of randomly selected findings—does not stop this process.
poor methods still won—albeit more slowly. This was true in even the most punitive version of the model, in which labs received a penalty 100 times the value of the original “pay-off” for a result that failed to replicate, and replication rates were high (half of all results were subject to replication efforts).
Smaldino and McElreath conclude that “top-performing laboratories will always be those who are able to cut corners”—even in a world with frequent replication. The Economist concludes that
[u]ltimately, therefore, the way to end the proliferation of bad science is not to nag people to behave better, or even to encourage replication, but for universities and funding agencies to stop rewarding researchers who publish copiously over those who publish fewer, but perhaps higher-quality papers.
In the Journal of Economic Perspectives, Tyler Cowen and Alex Tabarrok question whether NSF funds are allocated efficiently. They write:
First, a key question is not whether NSF funding is justified relative to laissez-faire, but rather, what is the marginal value of NSF funding given already existing government and nongovernment support for economic research? Second, we consider whether NSF funding might more productively be shifted in various directions that remain within the legal and traditional purview of the NSF. Such alternative focuses might include data availability, prizes rather than grants, broader dissemination of economic insights, and more. …
Public goods theory tells us that the National Science Foundation should support activities that are especially hard to support through traditional university, philanthropic, and private-sector sources. This insight suggests a simple test: to the extent that the NSF allocates funds to genuine public goods as opposed to subsidies on the margin, we ought to see a large difference in the kinds of projects the NSF supports compared to what the “market” sector supports. But what stands out from lists of prominent NSF grants … is how similar they look to lists of “good” research produced by today’s status quo.
The Economist reports about a simple test of the plausibility of published research, and that many well published psychology papers failed it.
The Economist reports about “outcome switching”—promoting empirical evidence collected in the context of a specific hypothesis test (that didn’t succeed) as support for a different hypothesis.
Outcome switching is a good example of the ways in which science can go wrong. This is a hot topic at the moment, with fields from psychology to cancer research going through a “replication crisis”, in which published results evaporate when people try to duplicate them.
A report in The Economist confirms what some economists always knew: The findings of laboratory experiments conducted by economists are not very reliable—but much more so than those conducted in medicine, psychology or genetics.
The Economist doubts that science is self-correcting as “many more dodgy results are published than are subsequently corrected or withdrawn.”
Referees do a bad job. Publishing pressure leads researchers to publish their (correct and incorrect) results multiple times. Replication studies are hard and thankless. And everyone seems to be getting the statistics wrong.
A researcher suffers from a type I error when she incorrectly rejects an hypothesis although it is true (false positive); and from a type II error when she incorrectly accepts an hypothesis although it is wrong (false negative). A good testing procedure minimises the type II error given a specified type I error that is, it maximises the power of the test. While employing a test with a power of 80% is considered good practice actual hypothesis testing often suffers from much lower power. As a consequence, many or even a majority of apparent “results” identified by a test might be wrong while most of the “non-results” are correctly identified. Quoting from the article:
… consider 1,000 hypotheses being tested of which just 100 are true (see chart). Studies with a power of 0.8 will find 80 of them, missing 20 because of false negatives. Of the 900 hypotheses that are wrong, 5%—that is, 45 of them—will look right because of type I errors. Add the false positives to the 80 true positives and you have 125 positive results, fully a third of which are specious. If you dropped the statistical power from 0.8 to 0.4, which would seem realistic for many fields, you would still have 45 false positives but only 40 true positives. More than half your positive results would be wrong.